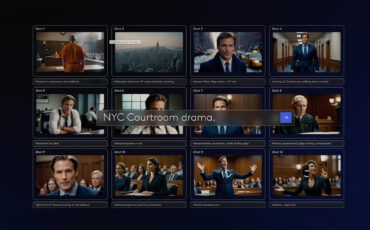
先月のOpenAIのビデオジェネレーターSoraの発表を見逃さなかっただろう。大きな話題となり、映画制作のコミュニティでは興奮と悲しみ、そして多くの疑問が巻き起こった。ジェネレーティブAIについて語るとき、常に出てくる差し迫った問題のひとつが、開発者がモデルのトレーニングに使っているデータだ。ウォール・ストリート・ジャーナル紙との最近のインタビューで、OpenAIの最高技術責任者(CTO)であるミラ・ムラティは、この質問に対する答えを出したくなかった(出せなかった)。彼女は、ソラがYouTubeの動画で訓練されたかどうかはわからないと付け加えた。これは重要な問題を提起している: 倫理とライセンスの観点から、これは何を意味するのだろうか?
念のために言っておく: SoraはOpenAIのtext-to-videoジェネレーターであり、簡単なテキスト記述に基づいて、一貫性があり、リアルで、詳細な60秒までのビデオクリップを作成することができると言われている。まだ一般には公開されていないが、公開されたショーケースは、すでにその可能性について激しい議論を巻き起こしている。仮説のひとつは、ストック映像に完全に取って代わるかもしれないということだ。もうひとつは、映像クリエイターがカメラの仕事を得るのが難しくなるというものだ。
個人的には、AIがクリエイティブや撮影の仕事を完全に取って代われるかどうかは懐疑的だが、それ以上に気になる別の疑問がある。例えばYouTubeの動画をモデルのトレーニングに使ったとして、一体どうやって商業目的でSoraを展開することが法的に許されるのだろうか?ライセンスの面ではどうなるのだろうか?
SoraはYouTube動画でトレーニングされたのか?
インタビューに先立ち、ウォール・ストリート・ジャーナルのジョアンナ・スターンは、ビデオクリップを生成するために使われたテキストプロンプトの束をOpenAIに提供した。OpenAiのミラ・ムラーティCTOとのディスカッションでは、Soraの長所と現在の限界を分析した。また、ジョアンナの関心事となったのは、出力された映像のいくつかが、有名なアニメや映画をひどく連想させたことだ。
モデルは『フェルディナンド』のクリップを見て、中国の店に入った牛がどう見えるべきかを知ったのだろうか?スポンジ・ボブのファンだったのだろうか?
ジョアンナ・スターン、ウォール・ストリート・ジャーナル紙のミラ・ムラティへのインタビューより引用


しかし、インタビューがSoraが学習するデータセットに触れると、ムラティは突然後退し、藪を叩き始めた。彼女は、Soraのモデル学習にYouTube、Facebook、Instagramのどの動画が使われているのか「よくわからない」とし、「一般に公開されているデータか、ライセンスされたデータ」(そもそもこの2つはまったく違うものだ!)という無難な答えに傾いた。ボディランゲージの専門家でなくても、OpenAIのCTOがこれらの質問に答えることに抵抗を感じていたことはわかるだろう。(彼女のリアクションは、以下のインタビュー動画の04:05から見ることができる)。
生成AIに関する著作権の課題
WSJによると、インタビューの後、ミラ・ムラーティは、SoraがオープンAIが提携しているシャッターストックのコンテンツを使用したことを確認したという。しかし、開発者がディープラーニング・モデルに投入した映像ソースはそれだけではないことが証明されている。
ムラーティの回答を詳しく見てみると、著作権と帰属の状況はさらに危機的なものとなっている。公に利用可能なデータ」という表現は、確かにOpenAIのSoraがYouTubeの公開コンテンツやソーシャルメディア上のコンテンツを含むインターネット全体をスクレイピングしていることを意味しているのかもしれない。例えば、YouTubeのコンテンツのライセンス条項は、そこでホストされているすべてのコンテンツのこのような利用を許可しているわけではない。
オンライン上の著作権を維持することは、それだけでも難しい分野だ。私は弁護士ではないが、常識的なこともある。例えば、サーチライト・ピクチャーズが『Poor Things(原題)』の予告編をYouTubeで公開したとしても、私がその予告編のクリップを商業的な作品に自由に使っていいということにはならない(あるいは、正しい帰属表示なしに私のブログで使っていいということにもならない)。同時に、OpenAIのSoraは、それにアクセスすることができ、学習目的で使用することができるだけでなく、利益を得ることもできる。
ある企業の反応
ジェネレーティブAIの著作権(およびライセンス)問題は、今に始まったことではない。この1年で、ニューヨーク・タイムズやゲッティイメージズのような大手メディア企業がAI開発者に対して(特に多いのはOpenAIに対して)起こした訴訟の数が増えていることを耳にした。
テキストを画像に変換するジェネレーターを使ったことがある人なら、AIが作成した画像に奇妙な単語を追加しているのを見たことがあるだろう。多くの場合、それらはストック・イメージの透かしや会社名を思い起こさせるもので、AI企業が使用するすべてのデータセットの権利を持っていないことを意味する。

残念ながら、AI開発者がオンラインで素材を使用することを防ぐような厳格な規制はまだなく、特定のデータがモデルのトレーニングに使用されたことを突き止め、証明することは不可能に近い。訴訟を起こすだけでなく、OpenAIのウェブクローラーをブロックして、自社のウェブサイトからコンテンツを取得できないようにしている企業もあれば、ライセンス契約を結んでいる企業もある(最新の例としては、ChatGPTにフランス語とスペイン語のコンテンツを提供するLe Monde and Prisa Mediaがある)。しかし、個人のアーティストや映像クリエイターとしてはどうするのか?この問題は未解決のままだ。
データセットを公開しないことは、ジェネレーティブAIの共通の問題
Soraの学習用データセットについて語りたがらないのは、OpenAIのCTOだけではない。同社は一般的に、使用しているソースについてほとんど言及しない。Soraのテクニカルペーパーでさえ、”Text-to-video generation systemsのトレーニングには、対応するテキストキャプション付きの大量の動画が必要だ “という曖昧なメモが見つかるだけだ。
同じ問題は、他のAI開発者、特に「小規模」「独立系」「研究系」を自称する開発者にも当てはまる。例えば、有名な画像ジェネレーターであるMidjourneyのウェブサイトを見て、彼らがどのようにモデルを訓練しているのか、そのデータについての情報を見つけようとしても、運が悪かったとしか言いようがない。この質問における透明性の欠如は、これらの企業が、使用しているデータに対する権利を持っていないという事実による法的問題を回避しようとしている最初の兆候となりうる。
もちろん例外もある。アドビは生成モデル「Firefly」を発表し、倫理的な問題に直接取り組み、使用したデータセットに関する情報を公開した。

しかし、彼らのアプローチには疑問が残る。Adobe Stockの投稿者は、自分たちの映像がAIのトレーニングフィールドになることを知らされていたのだろうか?彼らは同意したのだろうか?この事実は彼らの収益を増やすのだろうか?私はそうは思わない。
SoraがYouTubeの動画でトレーニングされたとしたら、それは何を意味するのか?
このように、私たちは明確な解決策を見いだせないまま、非常に厄介な状況に陥っている。ウォール・ストリート・ジャーナル紙との同じインタビューの中で、ミラ・ムラーティは、Soraはすでに今年中に一般公開されるだろうと述べた。彼女によると、OpenAIはこのツールを、彼らの画像ジェネレーターDALL-E 3と同様のコスト(現在1枚あたり約0.080ドル)で利用できるようにすることを目指している。しかし、もし学習データを明確にする方法を見つけられなかったり、映画制作者や映像クリエイターへの補償を行わなかったりすれば、彼らにとって事態は非常に緊迫したものになるかもしれない。少なくとも、大手スタジオや制作会社、成功しているYouTubeチャンネルは、OpenAIを著作権訴訟で葬り去るだろう。
画像出典:OpenAIのSoraが生成したビデオクリップのスクリーンショット。